集計のサンプルスクリプト
3名の参加者のサイモン課題のデータファイルを読み込んで集計してみます。PsychoPyが書き出したデータファイル(csvファイル)の中身はこんなかんじ。1行が1試行です。列 match が条件で,0が一致条件,1が不一致条件。列 task.corr は,正答ならば1,誤答ならば0。列 task.rt が反応時間(秒)です。

実際のサンプルデータはこちら。各ファイル40試行のデータ(一致条件20試行,不一致条件20試行)。仮に,c:\R\data フォルダに保存したものとします。
- aa_simon2019.csv(その1)
- bb_simon2019.csv(その2)
- cc_simon2019.csv(その3)
集計スクリプトはこちら。仮に,c:\R フォルダに保存したものとします。(ブラウザが直接開いてしまう場合は,下のリンクを右クリックして「名前をつけてリンク先を保存」とかなんかそういうのを選んでください。)
Rでスクリプトを実行します。
source("c:/R/simon2019_shukeidemo.R")
下のような結果になれば成功。
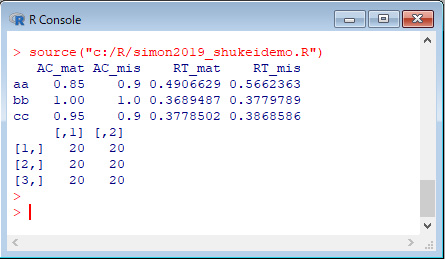
詳しくは,スクリプトの中身を見てください。初心者向けにコメントをつけてあります。
csvファイルの中身が文字化けする/読み込めない問題
テキストデータの文字コードは,日本語Windowsの標準はShift_JISですが,PsychoPyはUTF-8でcsvファイルを作成します(デフォルト設定の場合)。そのため,特にcsvファイルの中に日本語文字が含まれていると,うまく読めない・文字化けする,という問題が起こります。下のいずれかの方法で対処してください。
- 日本語文字を使わないようにする
- Rで文字コードを指定してcsvファイルを読み込む
- PsychoPy側で,Shift_JISでcsvファイルを書き出すようにする
プログラミングでは,日本語文字の扱いは半角英数より面倒なことが多く,慣れないうちは何かとトラブルの元です。日本語文字が必須でなければ,半角英数だけを使うようにしましょう。たとえば,条件を区別するだけの仮の名前なら,highとlowとかGakushuとTouseiのような英数文字だけの名前でも十分わかります。多少わかりにくくはなりますが,数値(1と0とか)や記号(AとBとか)にしてしまうのもアリです。
なお,半角文字でも," * & , ! などの記号類および半角スペースも,できるだけ使わないのが無難。アルファベットと数字だけ使うのが一番安全です。ファイル名やフォルダ名についても,日本語文字や記号類は使わないほうが,トラブルは起きにくくなります。
D <- read.csv("c:/R/data/aa_exp1.csv",encoding="UTF-8") #UTF-8を指定する場合
D <- read.csv("c:/R/data/aa_exp1.csv",encoding="Shift_JIS") #Shift_JISを指定する場合
実験プログラムの中にcodeコンポーネントを追加することでできます。こちらを参照のこと。
なお,Excelで.csvファイルがうまく開けない場合は,Microsoftのヘルプ「テキスト (.txt または .csv) ファイルのインポートまたはエクスポート」を参考にしてください。文字化けする場合は,文字コードに「Unicode (UTF-8)」を選べば解決します。
テキストデータ読み込みのいろいろ
Rでのデータ読み込み関係の詳細についてはこちらも参照のこと。また,read.csv() や関連コマンドのオンラインヘルプは,Rで
? read.csv
とすれば見られます。
Rで文字コードを指定してcsvファイルを読み込む
encodingオプションを使います。
D <- read.csv("c:/R/data/aa_exp1.csv",encoding="UTF-8") #UTF-8を指定する場合
D <- read.csv("c:/R/data/aa_exp1.csv",encoding="Shift_JIS") #Shift_JISを指定する場合
オプションは複数指定可能です。順番はなんでもOK。
D <- read.csv("c:/R/data/aa_exp1.csv",header=T,encoding="UTF-8") #カンマで区切って複数のオプションを指定
ヘッダを読み込む/無視する
上のサンプルデータの stim_col とか match のような,1行目に書かれた文字列を列の名前(ヘッダ)として使うかどうかを指定します。
D <- read.csv("c:/R/data/aa_exp1.csv",header=T) #ヘッダを読み込む
D <- read.csv("c:/R/data/aa_exp1.csv",header=F) #ヘッダを読み込まない
1行目からデータが書かれているのに1行目をヘッダとみなしてしまう場合には,header=Fと指定すると解決できます。
最初の数行を無視する
コメントや練習試行のデータなど,最初の数行は無視したいとき,skipオプションを使います。
D <- read.csv("c:/R/data/aa_exp1.csv",skip=2) #冒頭の2行を無視する
D <- read.csv("c:/R/data/aa_exp1.csv",skip=2,header=T) #併用可。ヘッダを除いた冒頭2行が無視される。
カンマ以外の文字で区切られたファイルを読み込み
sepオプションで区切り文字を指定できます。
D <- read.csv("c:/R/datafile.txt",sep="\t") #区切り文字がタブの場合
D <- read.csv("c:/R/datafile.txt",sep=",") #区切り文字がカンマの場合
read.delim()やread.table()コマンドを使っても読み込めます。